1
Machine Learning | An Introduction
Content
- Introduction
- Terminology
- Process
- Background Theory
- Machine Learning Approaches
Introduction
Machine Learning is undeniably one of the most influential and powerful technologies in today’s world. More importantly, we are far from seeing its full potential. There’s no doubt, it will continue to be making headlines for the foreseeable future. This article is designed as an introduction to the Machine Learning concepts, covering all the fundamental ideas without being too high level. Machine learning is a tool for turning information into knowledge. In the past 50 years, there has been an explosion of data. This mass of data is useless unless we analyse it and find the patterns hidden within. Machine learning techniques are used to automatically find the valuable underlying patterns within complex data that we would otherwise struggle to discover. The hidden patterns and knowledge about a problem can be used to predict future events and perform all kinds of complex decision making. We are drowning in information and starving for knowledge — John Naisbitt Most of us are unaware that we already interact with Machine Learning every single day. Every time we Google something, listen to a song or even take a photo, Machine Learning is becoming part of the engine behind it, constantly learning and improving from every interaction. It’s also behind world-changing advances like detecting cancer, creating new drugs and self-driving cars. The reason that Machine Learning is so exciting, is because it is a step away from all our previous rule-based systems of: if(x = y): do z Traditionally, software engineering combined human created rules with data to create answers to a problem. Instead, machine learning uses data and answers to discover the rules behind a problem. (Chollet, 2017) To learn the rules governing a phenomenon, machines have to go through a learning process, trying different rules and learning from how well they perform. Hence, why it’s known as Machine Learning. There are multiple forms of Machine Learning; supervised, unsupervised , semi-supervised and reinforcement learning. Each form of Machine Learning has differing approaches, but they all follow the same underlying process and theory. This explanation covers the general Machine Leaning concept and then focusses in on each approach.Terminology
 Dataset: A set of data examples, that contain features important to solving the problem.
Features: Important pieces of data that help us understand a problem. These are fed in to a Machine Learning algorithm to help it learn.
Model: The representation (internal model) of a phenomenon that a Machine Learning algorithm has learnt. It learns this from the data it is shown during training. The model is the output you get after training an algorithm. For example, a decision tree algorithm would be trained and produce a decision tree model.
Dataset: A set of data examples, that contain features important to solving the problem.
Features: Important pieces of data that help us understand a problem. These are fed in to a Machine Learning algorithm to help it learn.
Model: The representation (internal model) of a phenomenon that a Machine Learning algorithm has learnt. It learns this from the data it is shown during training. The model is the output you get after training an algorithm. For example, a decision tree algorithm would be trained and produce a decision tree model.
Process
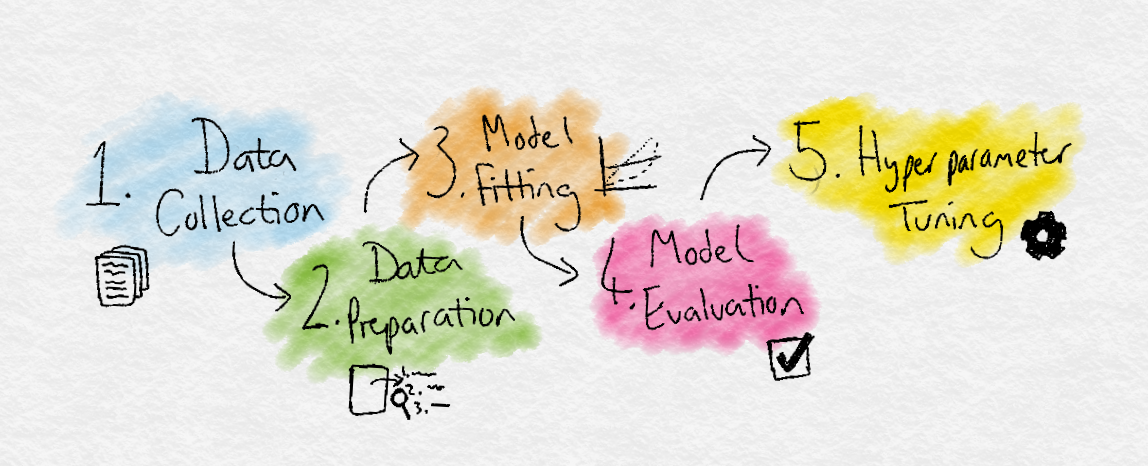 Data Collection: Collect the data that the algorithm will learn from.
Data Preparation: Format and engineer the data into the optimal format, extracting important features and performing dimensionality reduction.
Training: Also known as the fitting stage, this is where the Machine Learning algorithm actually learns by showing it the data that has been collected and prepared.
Evaluation: Test the model to see how well it performs.
Tuning: Fine tune the model to maximise it’s performance.
Data Collection: Collect the data that the algorithm will learn from.
Data Preparation: Format and engineer the data into the optimal format, extracting important features and performing dimensionality reduction.
Training: Also known as the fitting stage, this is where the Machine Learning algorithm actually learns by showing it the data that has been collected and prepared.
Evaluation: Test the model to see how well it performs.
Tuning: Fine tune the model to maximise it’s performance.
Background Theory
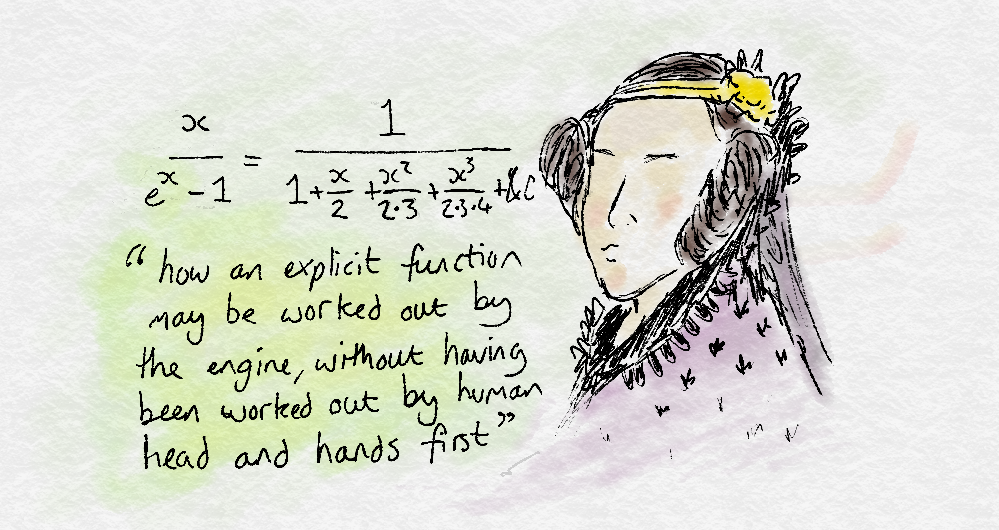 Origins
The Analytical Engine weaves algebraic patterns just as the Jaquard weaves flowers and leaves — Ada Lovelace
Ada Lovelace, one of the founders of computing, and perhaps the first computer programmer, realised that anything in the world could be described with math.
More importantly, this meant a mathematical formula can be created to derive the relationship representing any phenomenon. Ada Lovelace realised that machines had the potential to understand the world without the need for human assistance.
Around 200 years later, these fundamental ideas are critical in Machine Learning. No matter what the problem is, it’s information can be plotted onto a graph as data points. Machine Learning then tries to find the mathematical patterns and relationships hidden within the original information.
Probability Theory
Probability is orderly opinion… inference from data is nothing other than the revision of such opinion in the light of relevant new information — Thomas Bayes
Another mathematician, Thomas Bayes, founded ideas that are essential in the probability theory that is manifested into Machine Learning.
We live in a probabilistic world. Everything that happens has uncertainty attached to it. The Bayesian interpretation of probability is what Machine Learning is based upon. Bayesian probability means that we think of probability as quantifying the uncertainty of an event.
Because of this, we have to base our probabilities on the information available about an event, rather than counting the number of repeated trials. For example, when predicting a football match, instead of counting the total amount of times Manchester United have won against Liverpool, a Bayesian approach would use relevant information such as the current form, league placing and starting team.
The benefit of taking this approach is that probabilities can still be assigned to rare events, as the decision making process is based on relevant features and reasoning.
Origins
The Analytical Engine weaves algebraic patterns just as the Jaquard weaves flowers and leaves — Ada Lovelace
Ada Lovelace, one of the founders of computing, and perhaps the first computer programmer, realised that anything in the world could be described with math.
More importantly, this meant a mathematical formula can be created to derive the relationship representing any phenomenon. Ada Lovelace realised that machines had the potential to understand the world without the need for human assistance.
Around 200 years later, these fundamental ideas are critical in Machine Learning. No matter what the problem is, it’s information can be plotted onto a graph as data points. Machine Learning then tries to find the mathematical patterns and relationships hidden within the original information.
Probability Theory
Probability is orderly opinion… inference from data is nothing other than the revision of such opinion in the light of relevant new information — Thomas Bayes
Another mathematician, Thomas Bayes, founded ideas that are essential in the probability theory that is manifested into Machine Learning.
We live in a probabilistic world. Everything that happens has uncertainty attached to it. The Bayesian interpretation of probability is what Machine Learning is based upon. Bayesian probability means that we think of probability as quantifying the uncertainty of an event.
Because of this, we have to base our probabilities on the information available about an event, rather than counting the number of repeated trials. For example, when predicting a football match, instead of counting the total amount of times Manchester United have won against Liverpool, a Bayesian approach would use relevant information such as the current form, league placing and starting team.
The benefit of taking this approach is that probabilities can still be assigned to rare events, as the decision making process is based on relevant features and reasoning.
Machine Learning Approaches
 There are many approaches that can be taken when conducting Machine Learning. They are usually grouped into the areas listed below. Supervised and Unsupervised are well established approaches and the most commonly used. Semi-supervised and Reinforcement Learning are newer and more complex but have shown impressive results.
The No Free Lunch theorem is famous in Machine Learning. It states that there is no single algorithm that will work well for all tasks. Each task that you try to solve has it’s own idiosyncrasies. Therefore, there are lots of algorithms and approaches to suit each problems individual quirks. Plenty more styles of Machine Learning and AI will keep being introduced that best fit different problems.
Supervised Learning
Unsupervised Learning
Semi-supervised Learning
Reinforcement Learning
Supervised Learning
There are many approaches that can be taken when conducting Machine Learning. They are usually grouped into the areas listed below. Supervised and Unsupervised are well established approaches and the most commonly used. Semi-supervised and Reinforcement Learning are newer and more complex but have shown impressive results.
The No Free Lunch theorem is famous in Machine Learning. It states that there is no single algorithm that will work well for all tasks. Each task that you try to solve has it’s own idiosyncrasies. Therefore, there are lots of algorithms and approaches to suit each problems individual quirks. Plenty more styles of Machine Learning and AI will keep being introduced that best fit different problems.
Supervised Learning
Unsupervised Learning
Semi-supervised Learning
Reinforcement Learning
Supervised Learning
 In supervised learning, the goal is to learn the mapping (the rules) between a set of inputs and outputs.
For example, the inputs could be the weather forecast, and the outputs would be the visitors to the beach. The goal in supervised learning would be to learn the mapping that describes the relationship between temperature and number of beach visitors.
Example labelled data is provided of past input and output pairs during the learning process to teach the model how it should behave, hence, ‘supervised’ learning. For the beach example, new inputs can then be fed in of forecast temperature and the Machine learning algorithm will then output a future prediction for the number of visitors.
Being able to adapt to new inputs and make predictions is the crucial generalisation part of machine learning. In training, we want to maximise generalisation, so the supervised model defines the real ‘general’ underlying relationship. If the model is over-trained, we cause over-fitting to the examples used and the model would be unable to adapt to new, previously unseen inputs.
A side effect to be aware of in supervised learning that the supervision we provide introduces bias to the learning. The model can only be imitating exactly what it was shown, so it is very important to show it reliable, unbiased examples. Also, supervised learning usually requires a lot of data before it learns. Obtaining enough reliably labelled data is often the hardest and most expensive part of using supervised learning. (Hence why data has been called the new oil!)
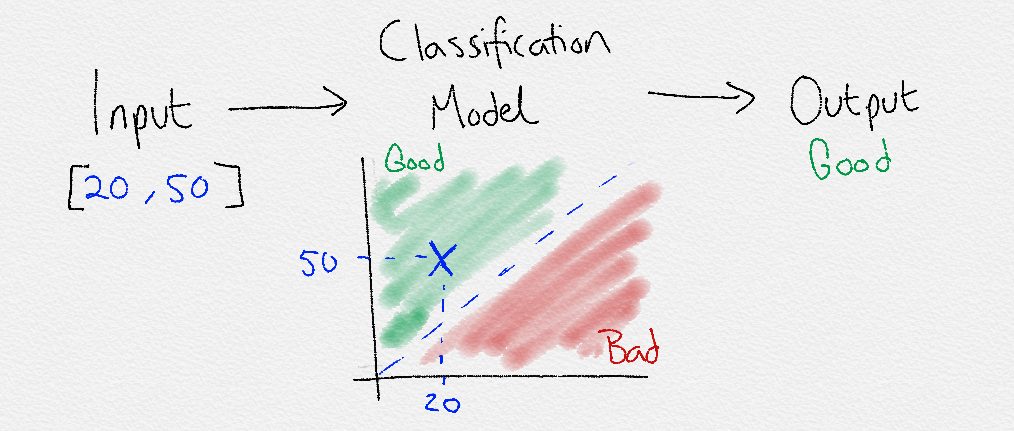
The output from a supervised Machine Learning model could be a category from a finite set e.g [low, medium, high] for the number of visitors to the beach:
Input [temperature=20] -> Model -> Output = [visitors=high]
When this is the case, it’s is deciding how to classify the input, and so is known as classification.
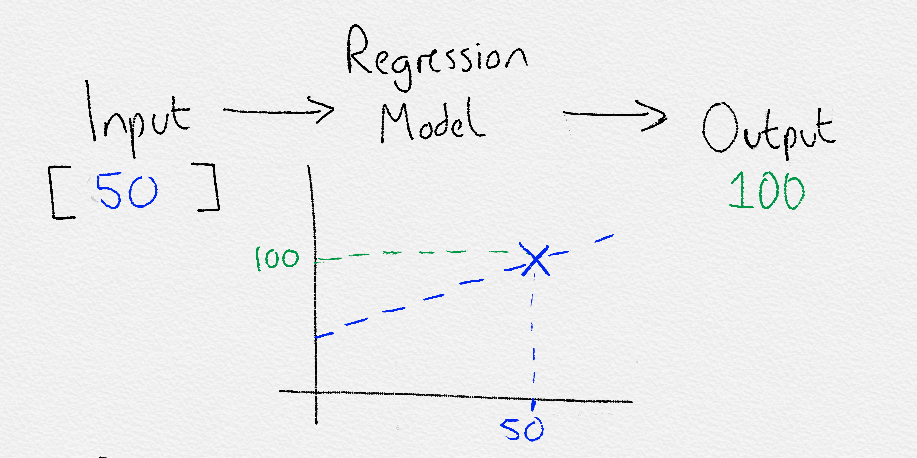
Alternatively, the output could be a real-world scalar (output a number):
Input [temperature=20] -> Model -> Output = [visitors=300]
When this is the case, it is known as regression.
Classification
In supervised learning, the goal is to learn the mapping (the rules) between a set of inputs and outputs.
For example, the inputs could be the weather forecast, and the outputs would be the visitors to the beach. The goal in supervised learning would be to learn the mapping that describes the relationship between temperature and number of beach visitors.
Example labelled data is provided of past input and output pairs during the learning process to teach the model how it should behave, hence, ‘supervised’ learning. For the beach example, new inputs can then be fed in of forecast temperature and the Machine learning algorithm will then output a future prediction for the number of visitors.
Being able to adapt to new inputs and make predictions is the crucial generalisation part of machine learning. In training, we want to maximise generalisation, so the supervised model defines the real ‘general’ underlying relationship. If the model is over-trained, we cause over-fitting to the examples used and the model would be unable to adapt to new, previously unseen inputs.
A side effect to be aware of in supervised learning that the supervision we provide introduces bias to the learning. The model can only be imitating exactly what it was shown, so it is very important to show it reliable, unbiased examples. Also, supervised learning usually requires a lot of data before it learns. Obtaining enough reliably labelled data is often the hardest and most expensive part of using supervised learning. (Hence why data has been called the new oil!)
The output from a supervised Machine Learning model could be a category from a finite set e.g [low, medium, high] for the number of visitors to the beach:
Input [temperature=20] -> Model -> Output = [visitors=high]
When this is the case, it’s is deciding how to classify the input, and so is known as classification.
Alternatively, the output could be a real-world scalar (output a number):
Input [temperature=20] -> Model -> Output = [visitors=300]
When this is the case, it is known as regression.
Classification
 Classification is used to group the similar data points into different sections in order to classify them. Machine Learning is used to find the rules that explain how to separate the different data points.
But how are the magical rules created? Well, there are multiple ways to discover the rules. They all focus on using data and answers to discover rules that linearly separate data points.
Linear separability is a key concept in machine learning. All that linear separability means is ‘can the different data points be separated by a line?’. So put simply, classification approaches try to find the best way to separate data points with a line.
The lines drawn between classes are known as the decision boundaries. The entire area that is chosen to define a class is known as the decision surface. The decision surface defines that if a data point falls within its boundaries, it will be assigned a certain class.
Regression
Classification is used to group the similar data points into different sections in order to classify them. Machine Learning is used to find the rules that explain how to separate the different data points.
But how are the magical rules created? Well, there are multiple ways to discover the rules. They all focus on using data and answers to discover rules that linearly separate data points.
Linear separability is a key concept in machine learning. All that linear separability means is ‘can the different data points be separated by a line?’. So put simply, classification approaches try to find the best way to separate data points with a line.
The lines drawn between classes are known as the decision boundaries. The entire area that is chosen to define a class is known as the decision surface. The decision surface defines that if a data point falls within its boundaries, it will be assigned a certain class.
Regression
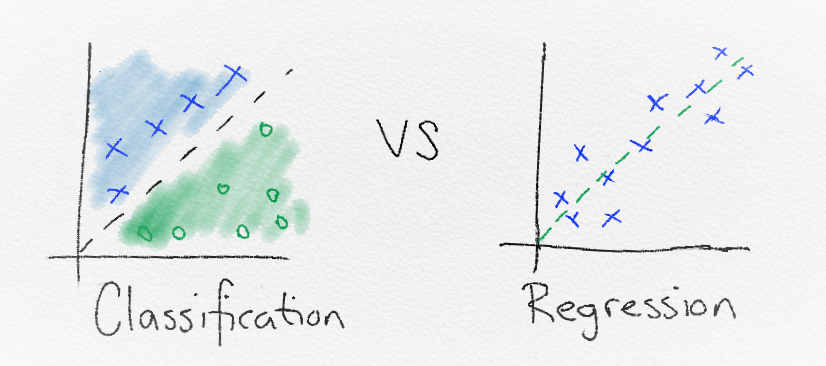 Regression is another form of supervised learning. The difference between classification and regression is that regression outputs a number rather than a class. Therefore, regression is useful when predicting number based problems like stock market prices, the temperature for a given day, or the probability of an event.
Examples
Regression is used in financial trading to find the patterns in stocks and other assets to decide when to buy/sell and make a profit. For classification, it is already being used to classify if an email you receive is spam.
Both the classification and regression supervised learning techniques can be extended to much more complex tasks. For example, tasks involving speech and audio. Image classification, object detection and chat bots are some examples.
A recent example shown below uses a model trained with supervised learning to realistically fake videos of people talking.
You might be wondering how does this complex image based task relate to classification or regression? Well, it comes back to everything in the world, even complex phenomenon, being fundamentally described with math and numbers. In this example, a neural network is still only outputting numbers like in regression. But in this example the numbers are the numerical 3d coordinate values of a facial mesh.
Unsupervised Learning
Regression is another form of supervised learning. The difference between classification and regression is that regression outputs a number rather than a class. Therefore, regression is useful when predicting number based problems like stock market prices, the temperature for a given day, or the probability of an event.
Examples
Regression is used in financial trading to find the patterns in stocks and other assets to decide when to buy/sell and make a profit. For classification, it is already being used to classify if an email you receive is spam.
Both the classification and regression supervised learning techniques can be extended to much more complex tasks. For example, tasks involving speech and audio. Image classification, object detection and chat bots are some examples.
A recent example shown below uses a model trained with supervised learning to realistically fake videos of people talking.
You might be wondering how does this complex image based task relate to classification or regression? Well, it comes back to everything in the world, even complex phenomenon, being fundamentally described with math and numbers. In this example, a neural network is still only outputting numbers like in regression. But in this example the numbers are the numerical 3d coordinate values of a facial mesh.
Unsupervised Learning
 In unsupervised learning, only input data is provided in the examples. There are no labelled example outputs to aim for. But it may be surprising to know that it is still possible to find many interesting and complex patterns hidden within data without any labels.
An example of unsupervised learning in real life would be sorting different colour coins into separate piles. Nobody taught you how to separate them, but by just looking at their features such as colour, you can see which colour coins are associated and cluster them into their correct groups.
An unsupervised learning algorithm (t-SNE) correctly clusters handwritten digits into groups, based only on their characteristics
Unsupervised learning can be harder than supervised learning, as the removal of supervision means the problem has become less defined. The algorithm has a less focused idea of what patterns to look for.
Think of it in your own learning. If you learnt to play the guitar by being supervised by a teacher, you would learn quickly by re-using the supervised knowledge of notes, chords and rhythms. But if you only taught yourself, you’d find it so much harder knowing where to start.
By being unsupervised in a laissez-faire teaching style, you start from a clean slate with less bias and may even find a new, better way solve a problem. Therefore, this is why unsupervised learning is also known as knowledge discovery. Unsupervised learning is very useful when conducting exploratory data analysis.
To find the interesting structures in unlabeled data, we use density estimation. The most common form of which is clustering. Among others, there is also dimensionality reduction, latent variable models and anomaly detection. More complex unsupervised techniques involve neural networks like Auto-encoders and Deep Belief Networks, but we won’t go into them in this introduction blog.
Clustering
In unsupervised learning, only input data is provided in the examples. There are no labelled example outputs to aim for. But it may be surprising to know that it is still possible to find many interesting and complex patterns hidden within data without any labels.
An example of unsupervised learning in real life would be sorting different colour coins into separate piles. Nobody taught you how to separate them, but by just looking at their features such as colour, you can see which colour coins are associated and cluster them into their correct groups.
An unsupervised learning algorithm (t-SNE) correctly clusters handwritten digits into groups, based only on their characteristics
Unsupervised learning can be harder than supervised learning, as the removal of supervision means the problem has become less defined. The algorithm has a less focused idea of what patterns to look for.
Think of it in your own learning. If you learnt to play the guitar by being supervised by a teacher, you would learn quickly by re-using the supervised knowledge of notes, chords and rhythms. But if you only taught yourself, you’d find it so much harder knowing where to start.
By being unsupervised in a laissez-faire teaching style, you start from a clean slate with less bias and may even find a new, better way solve a problem. Therefore, this is why unsupervised learning is also known as knowledge discovery. Unsupervised learning is very useful when conducting exploratory data analysis.
To find the interesting structures in unlabeled data, we use density estimation. The most common form of which is clustering. Among others, there is also dimensionality reduction, latent variable models and anomaly detection. More complex unsupervised techniques involve neural networks like Auto-encoders and Deep Belief Networks, but we won’t go into them in this introduction blog.
Clustering
 Unsupervised learning is mostly used for clustering. Clustering is the act of creating groups with differing characteristics. Clustering attempts to find various subgroups within a dataset. As this is unsupervised learning, we are not restricted to any set of labels and are free to choose how many clusters to create. This is both a blessing and a curse. Picking a model that has the correct number of clusters (complexity) has to be conducted via an empirical model selection process.
Association
In Association Learning you want to uncover the rules that describe your data. For example, if a person watches video A they will likely watch video B. Association rules are perfect for examples such as this where you want to find related items.
Anomaly Detection
The identification of rare or unusual items that differ from the majority of data. For example, your bank will use this to detect fraudulent activity on your card. Your normal spending habits will fall within a normal range of behaviors and values. But when someone tries to steal from you using your card the behavior will be different from your normal pattern. Anomaly detection uses unsupervised learning to separate and detect these strange occurrences.
Dimensionality Reduction
Dimensionality reduction aims to find the most important features to reduce the original feature set down into a smaller more efficient set that still encodes the important data.
For example, in predicting the number of visitors to the beach we might use the temperature, day of the week, month and number of events scheduled for that day as inputs. But the month might actually be not important for predicting the number of visitors.
Irrelevant features such as this can confuse a Machine Leaning algorithms and make them less efficient and accurate. By using dimensionality reduction, only the most important features are identified and used. Principal Component Analysis (PCA) is a commonly used technique.
Examples
In the real world, clustering has successfully been used to discover a new type of star by investigating what sub groups of star automatically form based on the stars characteristics. In marketing, it is regularly used to cluster customers into similar groups based on their behaviors and characteristics.
Association learning is used for recommending or finding related items. A common example is market basket analysis. In market basket analysis, association rules are found to predict other items a customer is likely to buy based on what they have placed in their basket. Amazon use this. If you place a new laptop in your basket, they recommend items like a laptop case via their association rules.
Anomaly detection is well suited in scenarios such as fraud detection and malware detection.
Semi-supervised learning
Semi-supervised learning is a mix between supervised and unsupervised approaches. The learning process isn’t closely supervised with example outputs for every single input, but we also don’t let the algorithm do its own thing and provide no form of feedback. Semi-supervised learning takes the middle road.
By being able to mix together a small amount of labelled data with a much larger unlabeled dataset it reduces the burden of having enough labelled data. Therefore, it opens up many more problems to be solved with machine learning.
Generative Adversarial Networks
Generative Adversarial Networks (GANs) have been a recent breakthrough with incredible results. GANs use two neural networks, a generator and discriminator. The generator generates output and the discriminator critiques it. By battling against each other they both become increasingly skilled.
By using a network to both generate input and another one to generate outputs there is no need for us to provide explicit labels every single time and so it can be classed as semi-supervised.
Examples
A perfect example is in medical scans, such as breast cancer scans. A trained expert is needed to label these which is time consuming and very expensive. Instead, an expert can label just a small set of breast cancer scans, and the semi-supervised algorithm would be able to leverage this small subset and apply it to a larger set of scans.
For me, GAN’s are one of the most impressive examples of semi-supervised learning. Below is a video where a Generative Adversarial Network uses unsupervised learning to map aspects from one image to another.
A neural network known as a GAN (generative adversarial network) is used to synthesize pictures, without using labelled training data.
Reinforcement Learning
The final type of machine learning is by far my favourite. It is less common and much more complex, but it has generated incredible results. It doesn’t use labels as such, and instead uses rewards to learn.
If you’re familiar with psychology, you’ll have heard of reinforcement learning. If not, you’ll already know the concept from how we learn in everyday life. In this approach, occasional positive and negative feedback is used to reinforce behaviours. Think of it like training a dog, good behaviours are rewarded with a treat and become more common. Bad behaviours are punished and become less common. This reward-motivated behaviour is key in reinforcement learning.
This is very similar to how we as humans also learn. Throughout our lives, we receive positive and negative signals and constantly learn from them. The chemicals in our brain are one of many ways we get these signals. When something good happens, the neurons in our brains provide a hit of positive neurotransmitters such as dopamine which makes us feel good and we become more likely to repeat that specific action. We don’t need constant supervision to learn like in supervised learning. By only giving the occasional reinforcement signals, we still learn very effectively.
One of the most exciting parts of Reinforcement Learning is that is a first step away from training on static datasets, and instead of being able to use dynamic, noisy data-rich environments. This brings Machine Learning closer to a learning style used by humans. The world is simply our noisy, complex data-rich environment.
Games are very popular in Reinforcement Learning research. They provide ideal data-rich environments. The scores in games are ideal reward signals to train reward-motivated behaviours. Additionally, time can be sped up in a simulated game environment to reduce overall training time.
A Reinforcement Learning algorithm just aims to maximise its rewards by playing the game over and over again. If you can frame a problem with a frequent ‘score’ as a reward, it is likely to be suited to Reinforcement Learning.
Examples
Reinforcement learning hasn’t been used as much in the real world due to how new and complex it is. But a real world example is using reinforcement learning to reduce data center running costs by controlling the cooling systems in a more efficient way. The algorithm learns a optimal policy of how to act in order to get the lowest energy costs. The lower the cost, the more reward it receives.
In research it is frequently used in games. Games of perfect information (where you can see the entire state of the environment) and imperfect information (where parts of the state are hidden e.g. the real world) have both seen incredible success that outperform humans.
Google DeepMind have used reinforcement learning in research to play Go and Atari games at superhuman levels.
A neural network known as Deep Q learns to play Breakout by itself using the score as rewards.
That’s all for the introduction to Machine Learning! Keep your eye out for more blogs coming soon that will go into more depth on specific topics.
Unsupervised learning is mostly used for clustering. Clustering is the act of creating groups with differing characteristics. Clustering attempts to find various subgroups within a dataset. As this is unsupervised learning, we are not restricted to any set of labels and are free to choose how many clusters to create. This is both a blessing and a curse. Picking a model that has the correct number of clusters (complexity) has to be conducted via an empirical model selection process.
Association
In Association Learning you want to uncover the rules that describe your data. For example, if a person watches video A they will likely watch video B. Association rules are perfect for examples such as this where you want to find related items.
Anomaly Detection
The identification of rare or unusual items that differ from the majority of data. For example, your bank will use this to detect fraudulent activity on your card. Your normal spending habits will fall within a normal range of behaviors and values. But when someone tries to steal from you using your card the behavior will be different from your normal pattern. Anomaly detection uses unsupervised learning to separate and detect these strange occurrences.
Dimensionality Reduction
Dimensionality reduction aims to find the most important features to reduce the original feature set down into a smaller more efficient set that still encodes the important data.
For example, in predicting the number of visitors to the beach we might use the temperature, day of the week, month and number of events scheduled for that day as inputs. But the month might actually be not important for predicting the number of visitors.
Irrelevant features such as this can confuse a Machine Leaning algorithms and make them less efficient and accurate. By using dimensionality reduction, only the most important features are identified and used. Principal Component Analysis (PCA) is a commonly used technique.
Examples
In the real world, clustering has successfully been used to discover a new type of star by investigating what sub groups of star automatically form based on the stars characteristics. In marketing, it is regularly used to cluster customers into similar groups based on their behaviors and characteristics.
Association learning is used for recommending or finding related items. A common example is market basket analysis. In market basket analysis, association rules are found to predict other items a customer is likely to buy based on what they have placed in their basket. Amazon use this. If you place a new laptop in your basket, they recommend items like a laptop case via their association rules.
Anomaly detection is well suited in scenarios such as fraud detection and malware detection.
Semi-supervised learning
Semi-supervised learning is a mix between supervised and unsupervised approaches. The learning process isn’t closely supervised with example outputs for every single input, but we also don’t let the algorithm do its own thing and provide no form of feedback. Semi-supervised learning takes the middle road.
By being able to mix together a small amount of labelled data with a much larger unlabeled dataset it reduces the burden of having enough labelled data. Therefore, it opens up many more problems to be solved with machine learning.
Generative Adversarial Networks
Generative Adversarial Networks (GANs) have been a recent breakthrough with incredible results. GANs use two neural networks, a generator and discriminator. The generator generates output and the discriminator critiques it. By battling against each other they both become increasingly skilled.
By using a network to both generate input and another one to generate outputs there is no need for us to provide explicit labels every single time and so it can be classed as semi-supervised.
Examples
A perfect example is in medical scans, such as breast cancer scans. A trained expert is needed to label these which is time consuming and very expensive. Instead, an expert can label just a small set of breast cancer scans, and the semi-supervised algorithm would be able to leverage this small subset and apply it to a larger set of scans.
For me, GAN’s are one of the most impressive examples of semi-supervised learning. Below is a video where a Generative Adversarial Network uses unsupervised learning to map aspects from one image to another.
A neural network known as a GAN (generative adversarial network) is used to synthesize pictures, without using labelled training data.
Reinforcement Learning
The final type of machine learning is by far my favourite. It is less common and much more complex, but it has generated incredible results. It doesn’t use labels as such, and instead uses rewards to learn.
If you’re familiar with psychology, you’ll have heard of reinforcement learning. If not, you’ll already know the concept from how we learn in everyday life. In this approach, occasional positive and negative feedback is used to reinforce behaviours. Think of it like training a dog, good behaviours are rewarded with a treat and become more common. Bad behaviours are punished and become less common. This reward-motivated behaviour is key in reinforcement learning.
This is very similar to how we as humans also learn. Throughout our lives, we receive positive and negative signals and constantly learn from them. The chemicals in our brain are one of many ways we get these signals. When something good happens, the neurons in our brains provide a hit of positive neurotransmitters such as dopamine which makes us feel good and we become more likely to repeat that specific action. We don’t need constant supervision to learn like in supervised learning. By only giving the occasional reinforcement signals, we still learn very effectively.
One of the most exciting parts of Reinforcement Learning is that is a first step away from training on static datasets, and instead of being able to use dynamic, noisy data-rich environments. This brings Machine Learning closer to a learning style used by humans. The world is simply our noisy, complex data-rich environment.
Games are very popular in Reinforcement Learning research. They provide ideal data-rich environments. The scores in games are ideal reward signals to train reward-motivated behaviours. Additionally, time can be sped up in a simulated game environment to reduce overall training time.
A Reinforcement Learning algorithm just aims to maximise its rewards by playing the game over and over again. If you can frame a problem with a frequent ‘score’ as a reward, it is likely to be suited to Reinforcement Learning.
Examples
Reinforcement learning hasn’t been used as much in the real world due to how new and complex it is. But a real world example is using reinforcement learning to reduce data center running costs by controlling the cooling systems in a more efficient way. The algorithm learns a optimal policy of how to act in order to get the lowest energy costs. The lower the cost, the more reward it receives.
In research it is frequently used in games. Games of perfect information (where you can see the entire state of the environment) and imperfect information (where parts of the state are hidden e.g. the real world) have both seen incredible success that outperform humans.
Google DeepMind have used reinforcement learning in research to play Go and Atari games at superhuman levels.
A neural network known as Deep Q learns to play Breakout by itself using the score as rewards.
That’s all for the introduction to Machine Learning! Keep your eye out for more blogs coming soon that will go into more depth on specific topics.