1
An Introduction to Unity ML-Agents
Train a reinforcement learning agent to jump over walls.
 This article is part of a new free course on Deep Reinforcement Learning with Unity. Where we’ll create agents with TensorFlow that learn to play video games using the Unity game engine 🕹. Check the syllabus here.
If you never study Deep Reinforcement Learning before, you need to check the free course Deep Reinforcement Learning with Tensorflow.
The past few years have witnessed breakthroughs in reinforcement learning (RL). From the first successful use of RL by a deep learning model for learning a policy from pixel input in 2013 to the OpenAI Dexterity program in 2019, we live in an exciting moment in RL research.
Consequently, we need, as RL researchers, to create more and more complex environments and Unity helps us to do that. Unity ML-Agents toolkit is a new plugin based on the game engine Unity that allows us to use the Unity Game Engine as an environment builder to train agents.
This article is part of a new free course on Deep Reinforcement Learning with Unity. Where we’ll create agents with TensorFlow that learn to play video games using the Unity game engine 🕹. Check the syllabus here.
If you never study Deep Reinforcement Learning before, you need to check the free course Deep Reinforcement Learning with Tensorflow.
The past few years have witnessed breakthroughs in reinforcement learning (RL). From the first successful use of RL by a deep learning model for learning a policy from pixel input in 2013 to the OpenAI Dexterity program in 2019, we live in an exciting moment in RL research.
Consequently, we need, as RL researchers, to create more and more complex environments and Unity helps us to do that. Unity ML-Agents toolkit is a new plugin based on the game engine Unity that allows us to use the Unity Game Engine as an environment builder to train agents.
 Source: Unity ML-Agents Toolkit Github Repository
From playing football, learning to walk, to jump big walls, to train a cute doggy to catch sticks, Unity ML-Agents Toolkit provides a ton of amazing pre-made environment.
Furthermore, during this free course, we will also create new learning environments.
For now, we’ll learn how Unity ML-Agents works and at the end of the article, you’ll train an agent to learn jumping over walls.
Source: Unity ML-Agents Toolkit Github Repository
From playing football, learning to walk, to jump big walls, to train a cute doggy to catch sticks, Unity ML-Agents Toolkit provides a ton of amazing pre-made environment.
Furthermore, during this free course, we will also create new learning environments.
For now, we’ll learn how Unity ML-Agents works and at the end of the article, you’ll train an agent to learn jumping over walls.
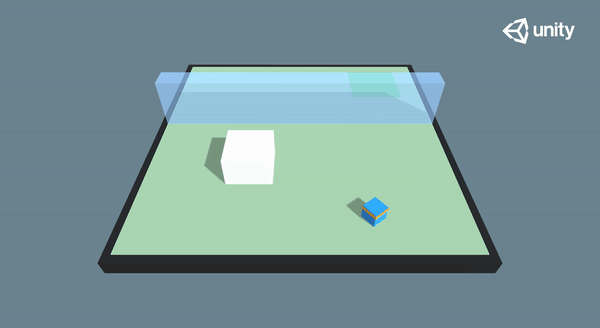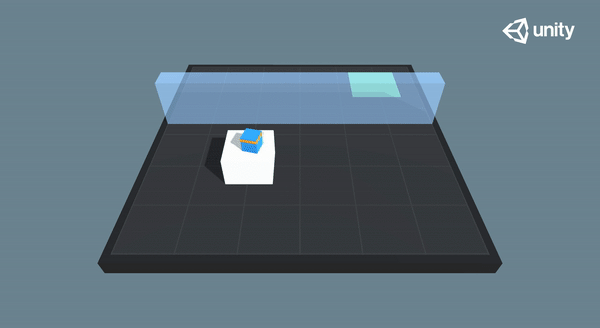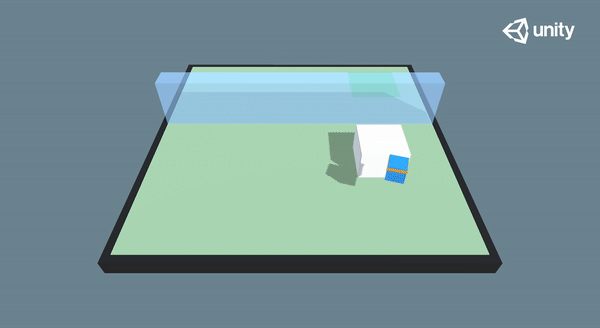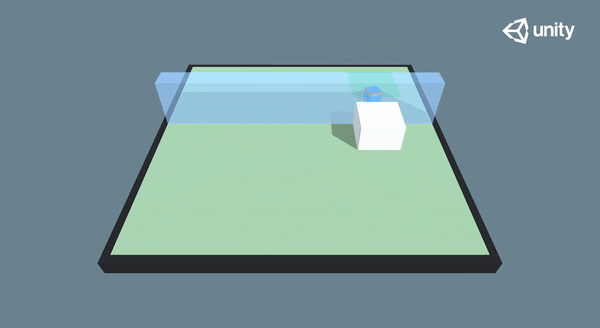 But first, there are some requirements:
This is not a reinforcement learning introductory course, if you don’t have skills in Deep Reinforcement Learning before, you need to check the free course Deep Reinforcement Learning with Tensorflow.
Moreover, this is not a course about Unity, so you need to have some Unity basic skills. if it’s not the case you should definitely check out their amazing course for beginners: Create with Code.
So let’s get started!
How Unity ML-Agents works?
What’s Unity ML-Agents?
Unity ML-Agents is a new plugin for the game engine Unity that allows us to create or use pre-made environments to train our agents.
It’s developed by Unity Technologies, the developers of Unity, one of the best game engine ever. This is used by the creators of Firewatch, Gone Home, Cuphead and also a lot of AAA games.
But first, there are some requirements:
This is not a reinforcement learning introductory course, if you don’t have skills in Deep Reinforcement Learning before, you need to check the free course Deep Reinforcement Learning with Tensorflow.
Moreover, this is not a course about Unity, so you need to have some Unity basic skills. if it’s not the case you should definitely check out their amazing course for beginners: Create with Code.
So let’s get started!
How Unity ML-Agents works?
What’s Unity ML-Agents?
Unity ML-Agents is a new plugin for the game engine Unity that allows us to create or use pre-made environments to train our agents.
It’s developed by Unity Technologies, the developers of Unity, one of the best game engine ever. This is used by the creators of Firewatch, Gone Home, Cuphead and also a lot of AAA games.
 Firewatch was made with Unity
The three components
With Unity ML-Agents, you have three important components.
Firewatch was made with Unity
The three components
With Unity ML-Agents, you have three important components.
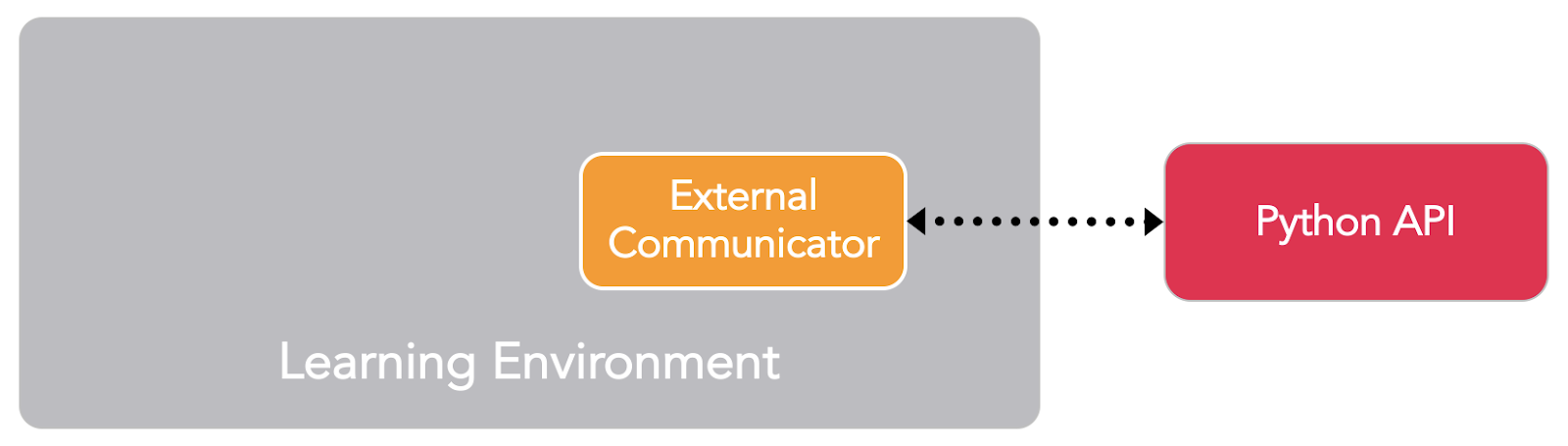 Source: Unity ML-Agents Documentation
The first is the Learning Component (on Unity), that contains the Unity scene and the environment elements.
The second is the Python API that contains the RL algorithms (such as PPO and SAC). We use this API to launch training, to test, etc. It communicates with the Learning environment through the external communicator.
Inside the Learning Component
Inside the Learning Component, we have different elements:
Source: Unity ML-Agents Documentation
The first is the Learning Component (on Unity), that contains the Unity scene and the environment elements.
The second is the Python API that contains the RL algorithms (such as PPO and SAC). We use this API to launch training, to test, etc. It communicates with the Learning environment through the external communicator.
Inside the Learning Component
Inside the Learning Component, we have different elements:
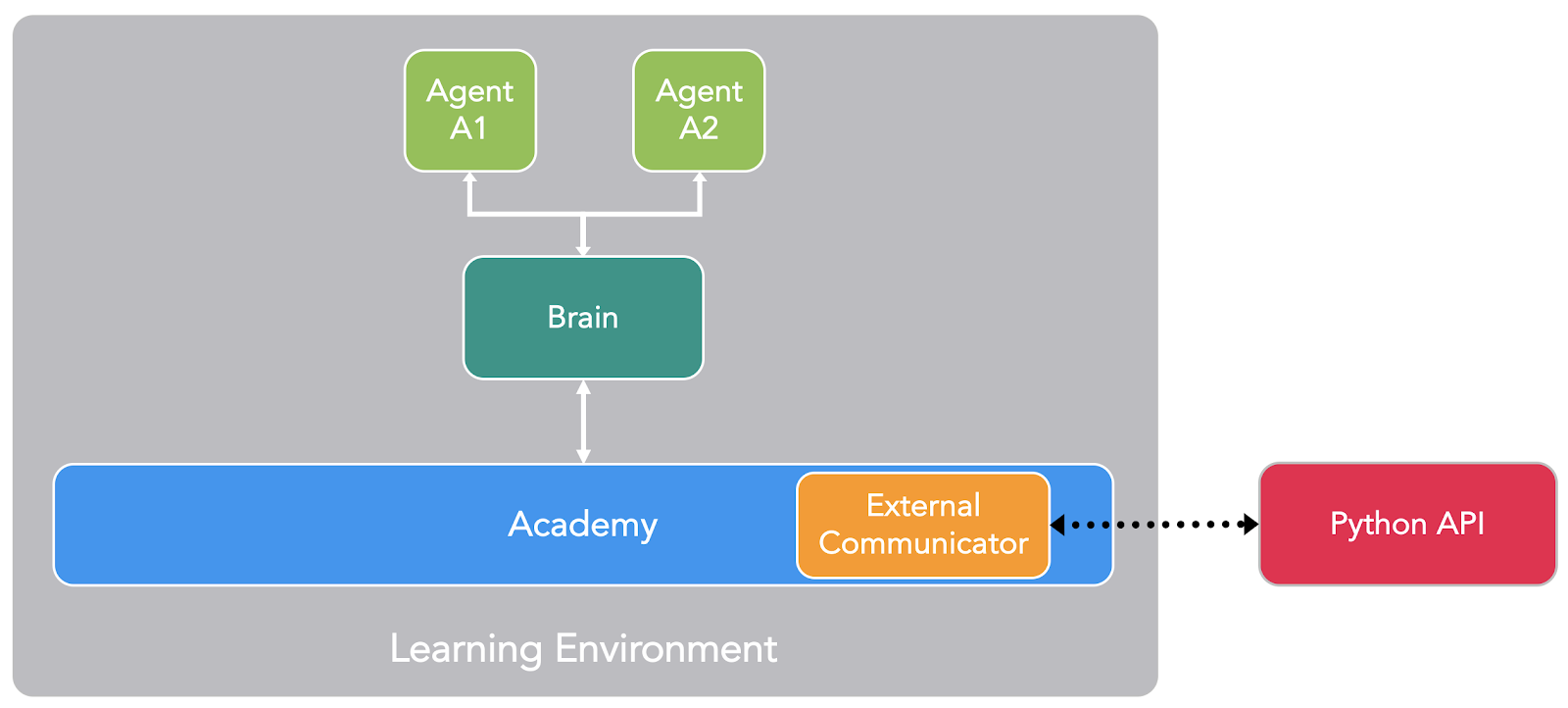 Source: Unity ML-Agents Documentation
The first is the Agent, the actor of the scene. He’s him that we’re going to train by optimizing his policy (that will tell us what action to take at each state) called Brain.
Finally, there is the Academy, this element orchestrates agents and their decision-making process. Think of this Academy as a maestro that handles the requests from the python API.
To better understand its role let’s remember the RL process. This can be modeled as a loop that works like this:
Source: Unity ML-Agents Documentation
The first is the Agent, the actor of the scene. He’s him that we’re going to train by optimizing his policy (that will tell us what action to take at each state) called Brain.
Finally, there is the Academy, this element orchestrates agents and their decision-making process. Think of this Academy as a maestro that handles the requests from the python API.
To better understand its role let’s remember the RL process. This can be modeled as a loop that works like this:
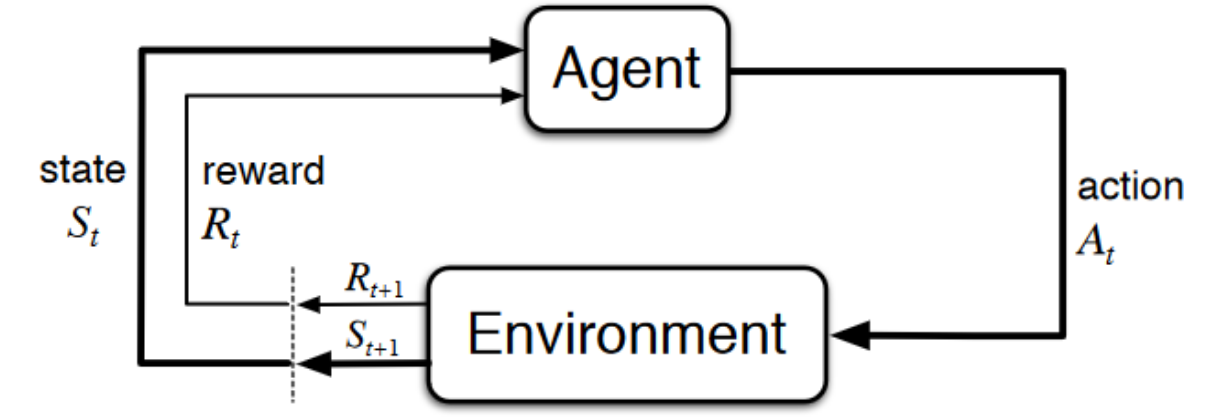 Source: Sutton’s Book
Now, let’s imagine an agent learning to play a platform game. The RL process looks like this:
Our agent receives state S0 from the environment — we receive the first frame of our game (environment).
Based on the state S0, the agent takes an action A0 — our agent will move to the right.
The environment transitions to a new state S1.
Give a reward R1 to the agent — we’re not dead (Positive Reward +1).
This RL loop outputs a sequence of state, action, and reward. The goal of the agent is to maximize the expected cumulative reward.
Source: Sutton’s Book
Now, let’s imagine an agent learning to play a platform game. The RL process looks like this:
Our agent receives state S0 from the environment — we receive the first frame of our game (environment).
Based on the state S0, the agent takes an action A0 — our agent will move to the right.
The environment transitions to a new state S1.
Give a reward R1 to the agent — we’re not dead (Positive Reward +1).
This RL loop outputs a sequence of state, action, and reward. The goal of the agent is to maximize the expected cumulative reward.
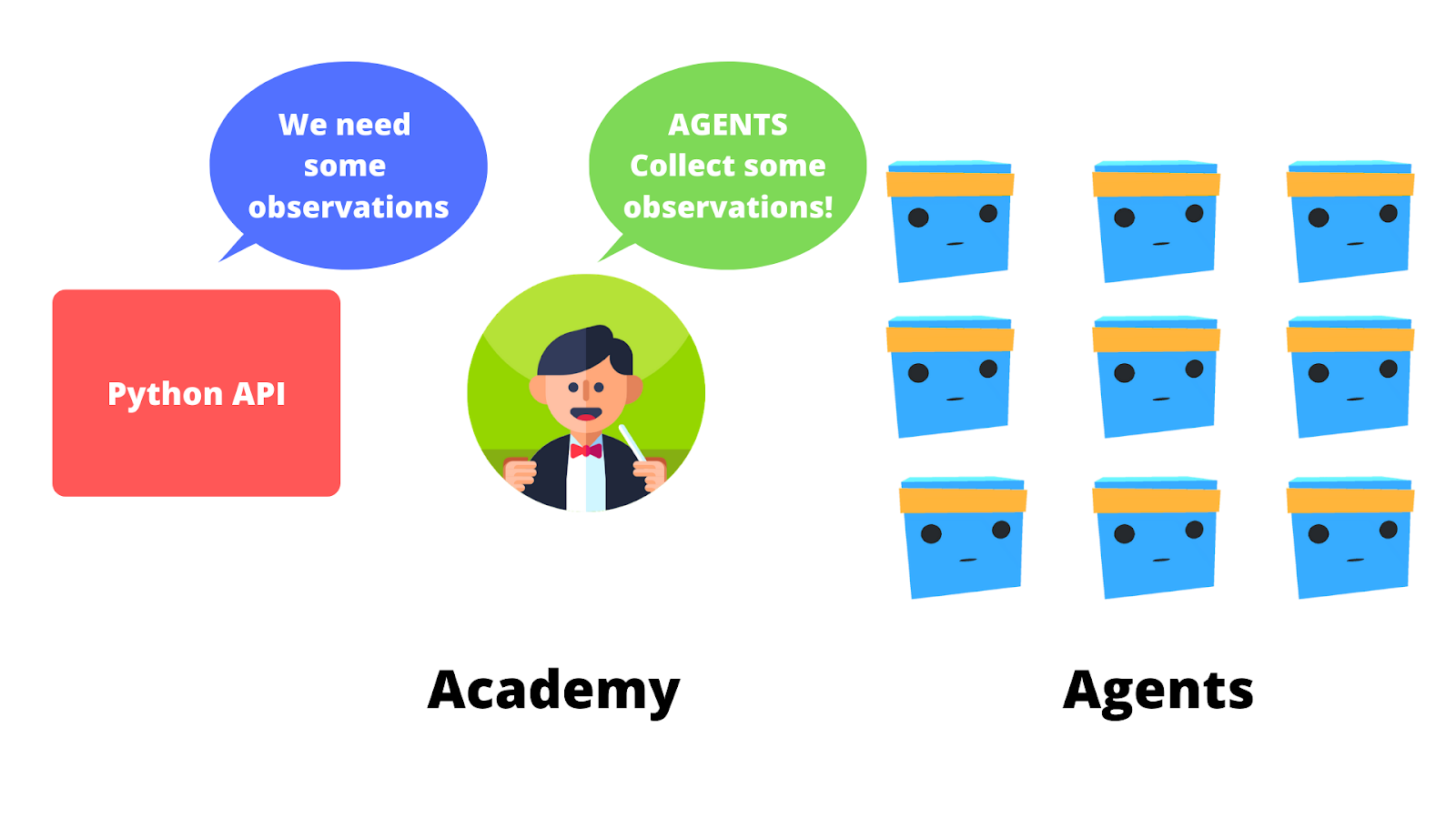 In fact, the Academy will be the one that will send the order to our Agents and ensure that agents are in sync:
Collect Observations
Select your action using your policy
Take the Action
Reset if you reached the max step or if you’re done.
Train an agent to jump walls
So now that we understand how Unity ML-Agents works, let’s train an agent to jump off the wall.
We published our trained models on github, you can download them here.
The Wall Jump Environment
The goal in this environment is to train our agent to go on the green tile.
However, there are 3 situations:
The first, you have no walls, our agent just needs to go on the green tile.
In fact, the Academy will be the one that will send the order to our Agents and ensure that agents are in sync:
Collect Observations
Select your action using your policy
Take the Action
Reset if you reached the max step or if you’re done.
Train an agent to jump walls
So now that we understand how Unity ML-Agents works, let’s train an agent to jump off the wall.
We published our trained models on github, you can download them here.
The Wall Jump Environment
The goal in this environment is to train our agent to go on the green tile.
However, there are 3 situations:
The first, you have no walls, our agent just needs to go on the green tile.
 No Wall situation
In the second situation, the agent needs to learn to jump in order to reach the green tile.
No Wall situation
In the second situation, the agent needs to learn to jump in order to reach the green tile.
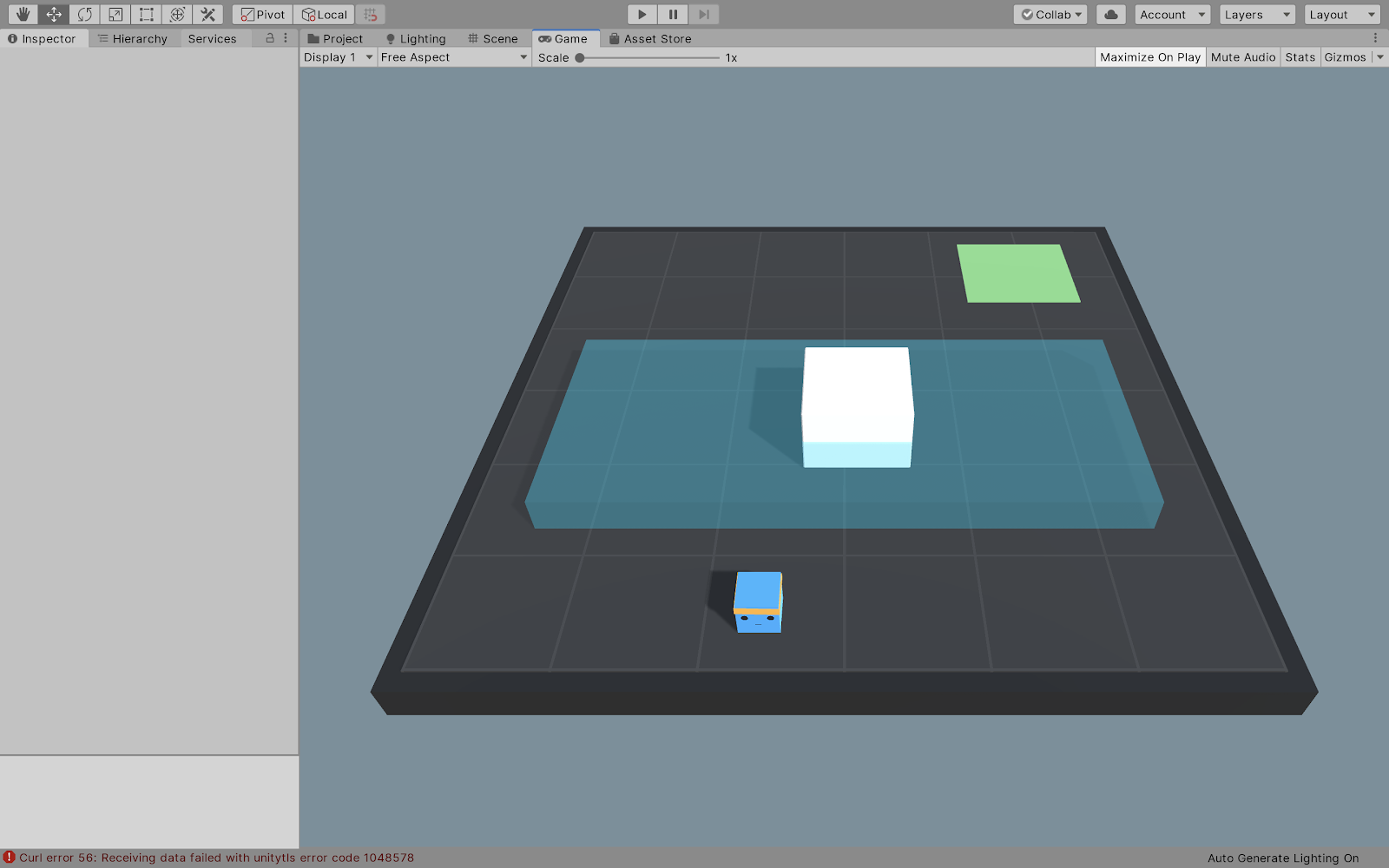
 Small Wall Situation
Finally, in the hardest situation, our agent will not be able to jump as high as the wall is so he needs to push the white block in order to jump on it to be able to jump over the wall.
Small Wall Situation
Finally, in the hardest situation, our agent will not be able to jump as high as the wall is so he needs to push the white block in order to jump on it to be able to jump over the wall.
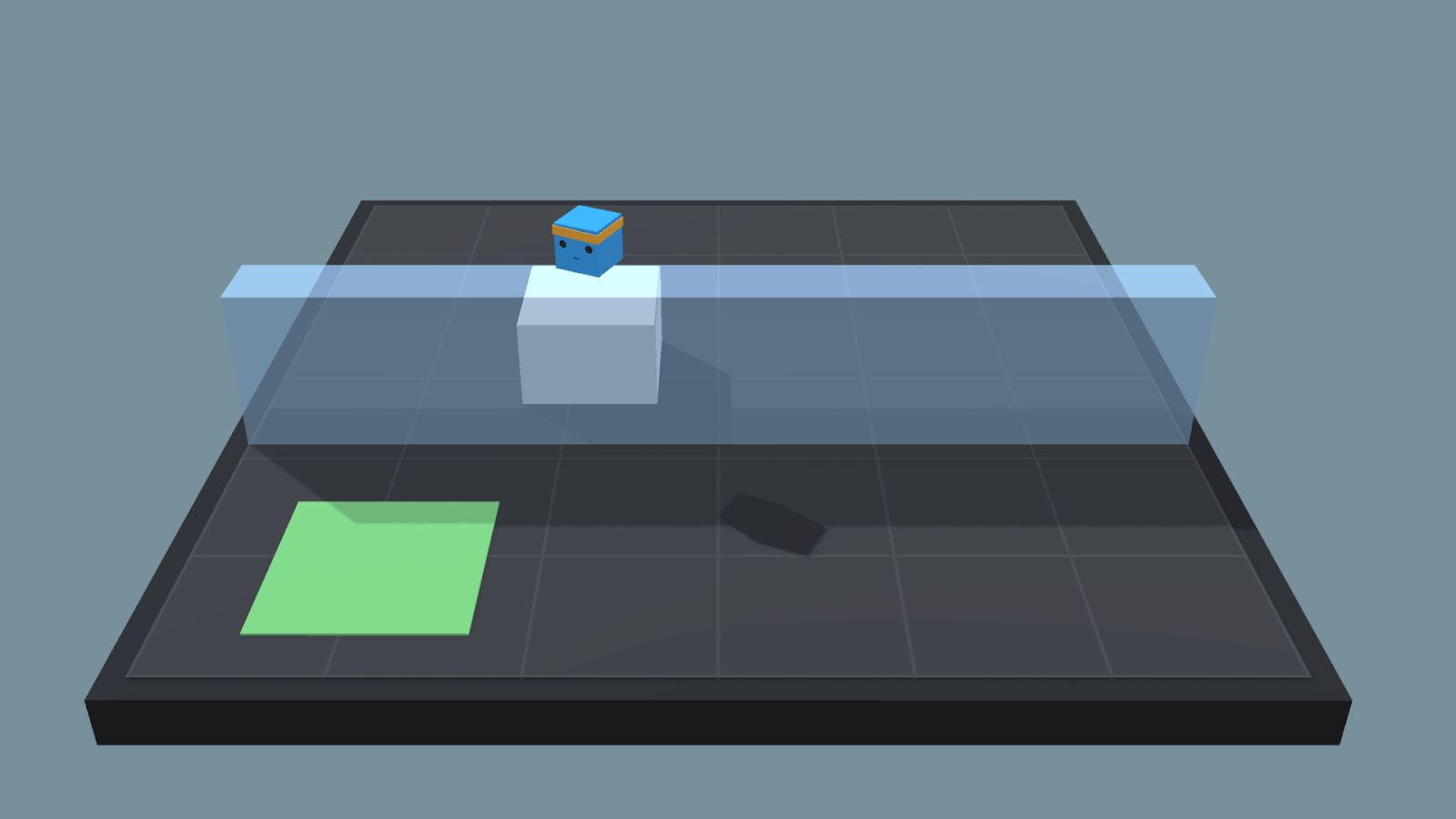
 Big Wall Situation
We’ll learn two different policies depending on the height of the wall:
The first SmallWallJump will be learned during the no wall and low wall situations.
The second, BigWallJump, will be learned during the high wall situations.
In terms of observation, we don’t use normal vision (frame) but 14 raycasts that can each detect 4 possible objects. Think of raycasts as lasers that will detect if it passes through object.
We also use the global position of the agent and whether or not is grounded.
Big Wall Situation
We’ll learn two different policies depending on the height of the wall:
The first SmallWallJump will be learned during the no wall and low wall situations.
The second, BigWallJump, will be learned during the high wall situations.
In terms of observation, we don’t use normal vision (frame) but 14 raycasts that can each detect 4 possible objects. Think of raycasts as lasers that will detect if it passes through object.
We also use the global position of the agent and whether or not is grounded.
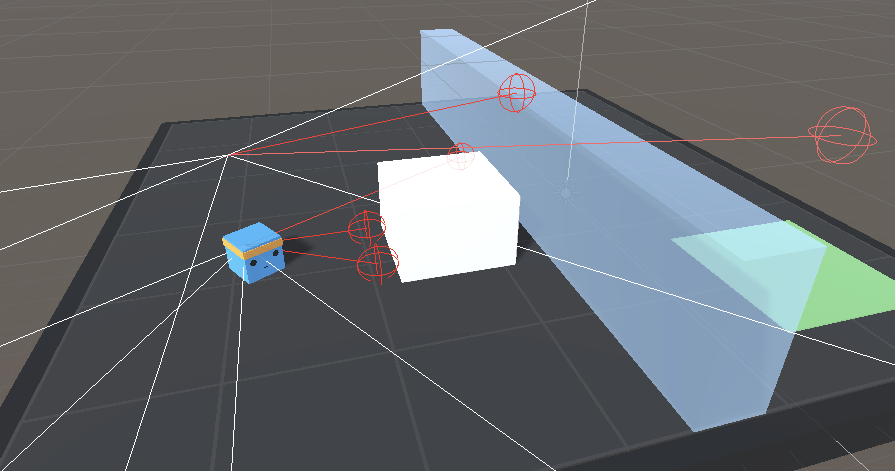 Source: Unity ML-Agents Documentation
The action space is discrete with 4 branches:
Source: Unity ML-Agents Documentation
The action space is discrete with 4 branches:
 Our goal is to hit the benchmark with a mean reward of 0.8.
Let’s jump!
First of all, let’s open the UnitySDK project.
In the examples search for WallJump and open the scene.
You see in the scene, a lot of Agents, each of them comes from the same Prefab and they all share the same Brain.
Our goal is to hit the benchmark with a mean reward of 0.8.
Let’s jump!
First of all, let’s open the UnitySDK project.
In the examples search for WallJump and open the scene.
You see in the scene, a lot of Agents, each of them comes from the same Prefab and they all share the same Brain.
 Multiple copies of the same Agent Prefab.
In fact, as we do in classical Deep Reinforcement Learning when we launched multiple instances of a game (for instance 128 parallel environments) we do the same hereby copy and paste the agents, in order to have more various states.
So, first, because we want to train our agent from scratch, we need to remove the brains from the agent. We need to go to the prefabs folder and open the Prefab.
Now in the Prefab hierarchy, select the Agent and go into the inspector.
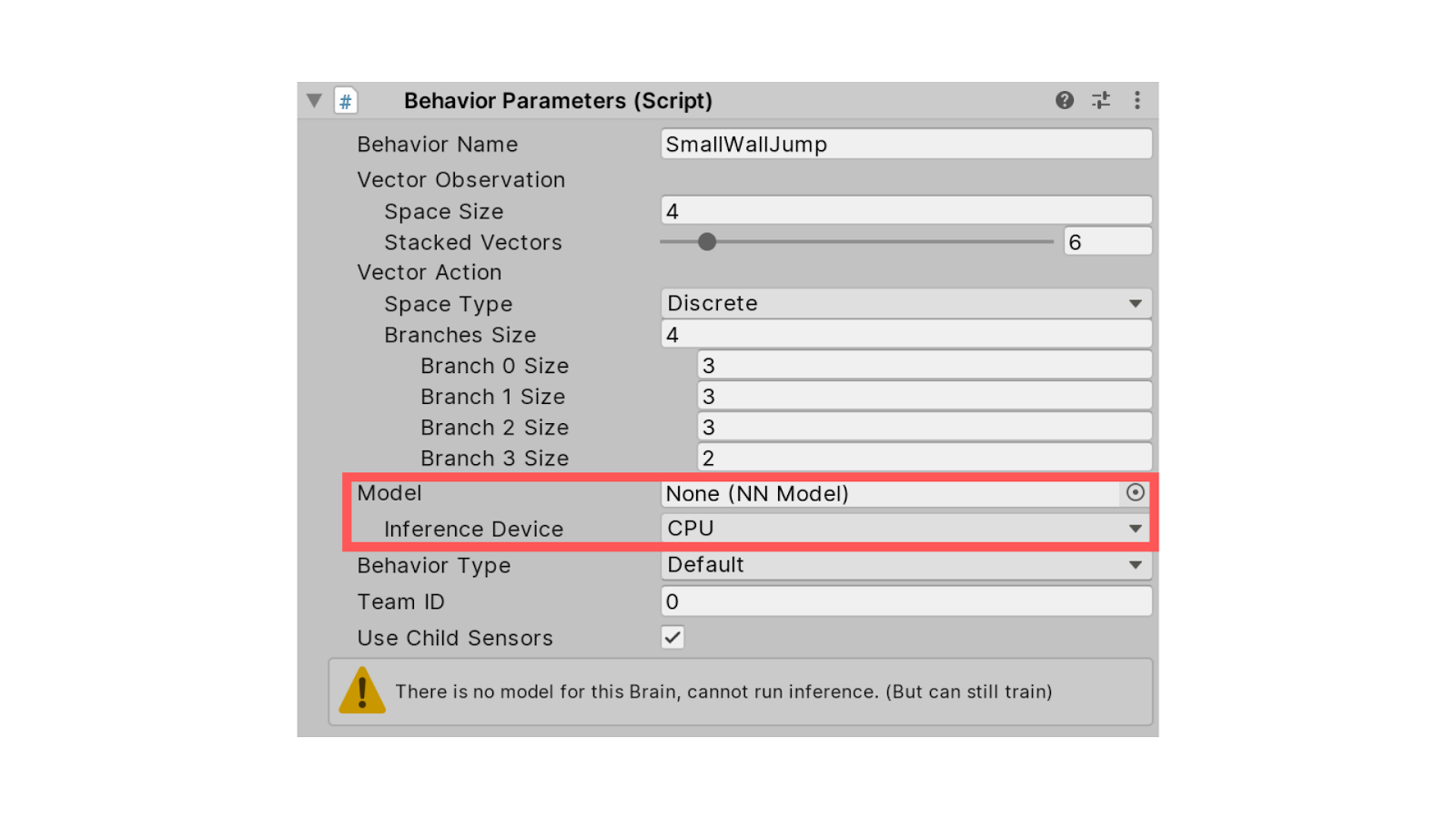
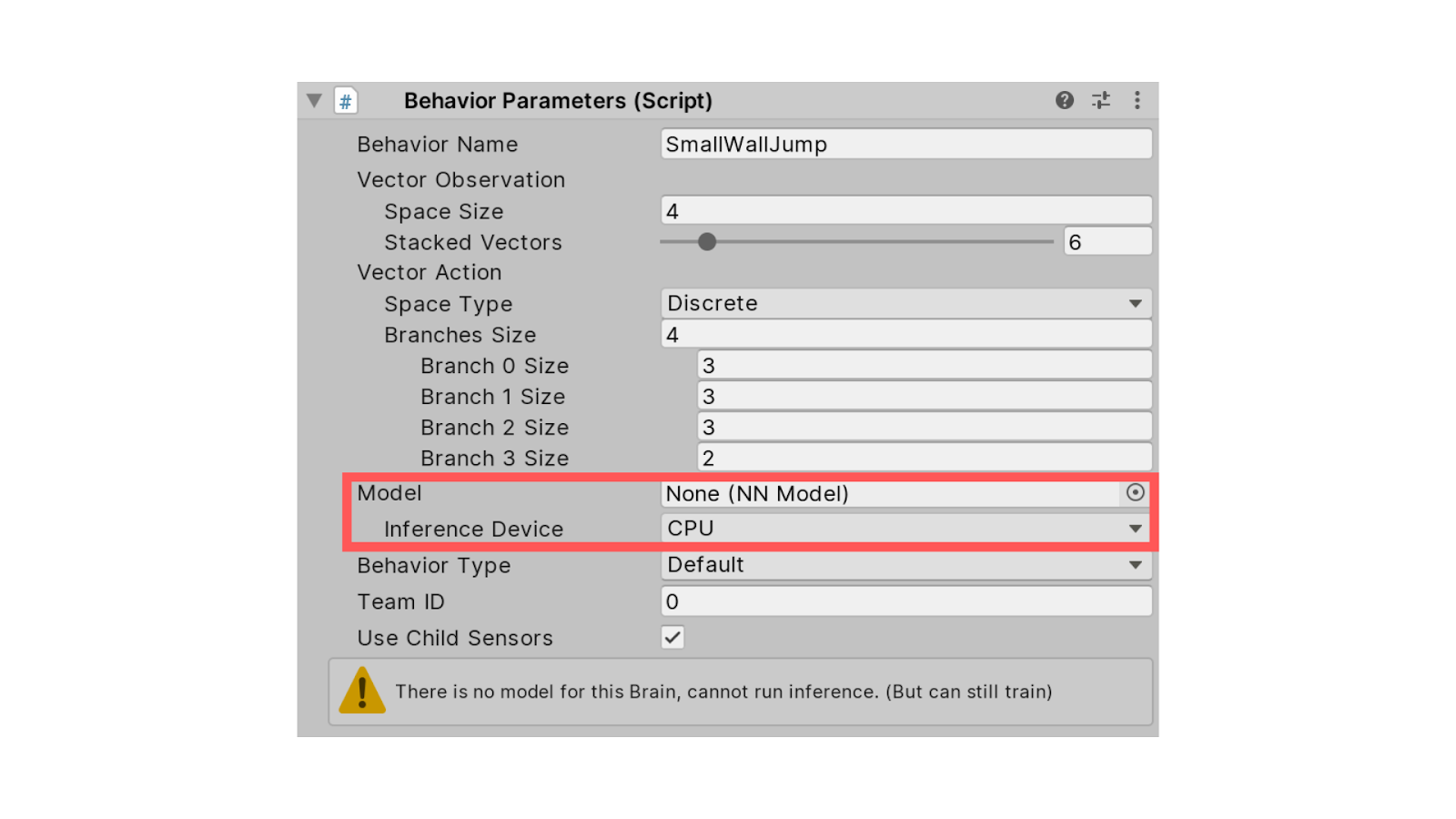
First, in Behavior Parameters, we need to remove the Model. If you have some GPUs you can change Inference Device from CPU to GPU.
Multiple copies of the same Agent Prefab.
In fact, as we do in classical Deep Reinforcement Learning when we launched multiple instances of a game (for instance 128 parallel environments) we do the same hereby copy and paste the agents, in order to have more various states.
So, first, because we want to train our agent from scratch, we need to remove the brains from the agent. We need to go to the prefabs folder and open the Prefab.
Now in the Prefab hierarchy, select the Agent and go into the inspector.
First, in Behavior Parameters, we need to remove the Model. If you have some GPUs you can change Inference Device from CPU to GPU.
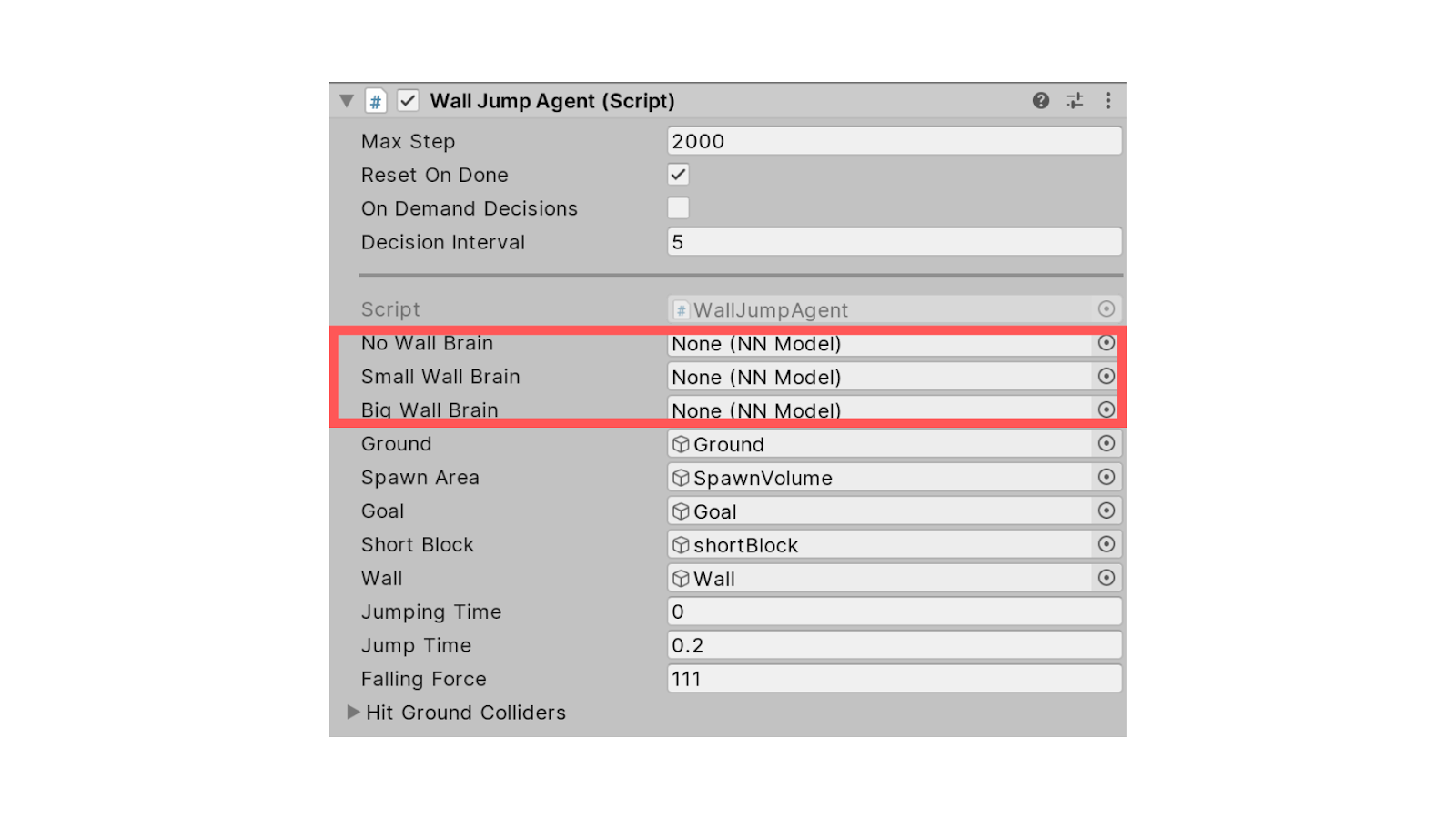
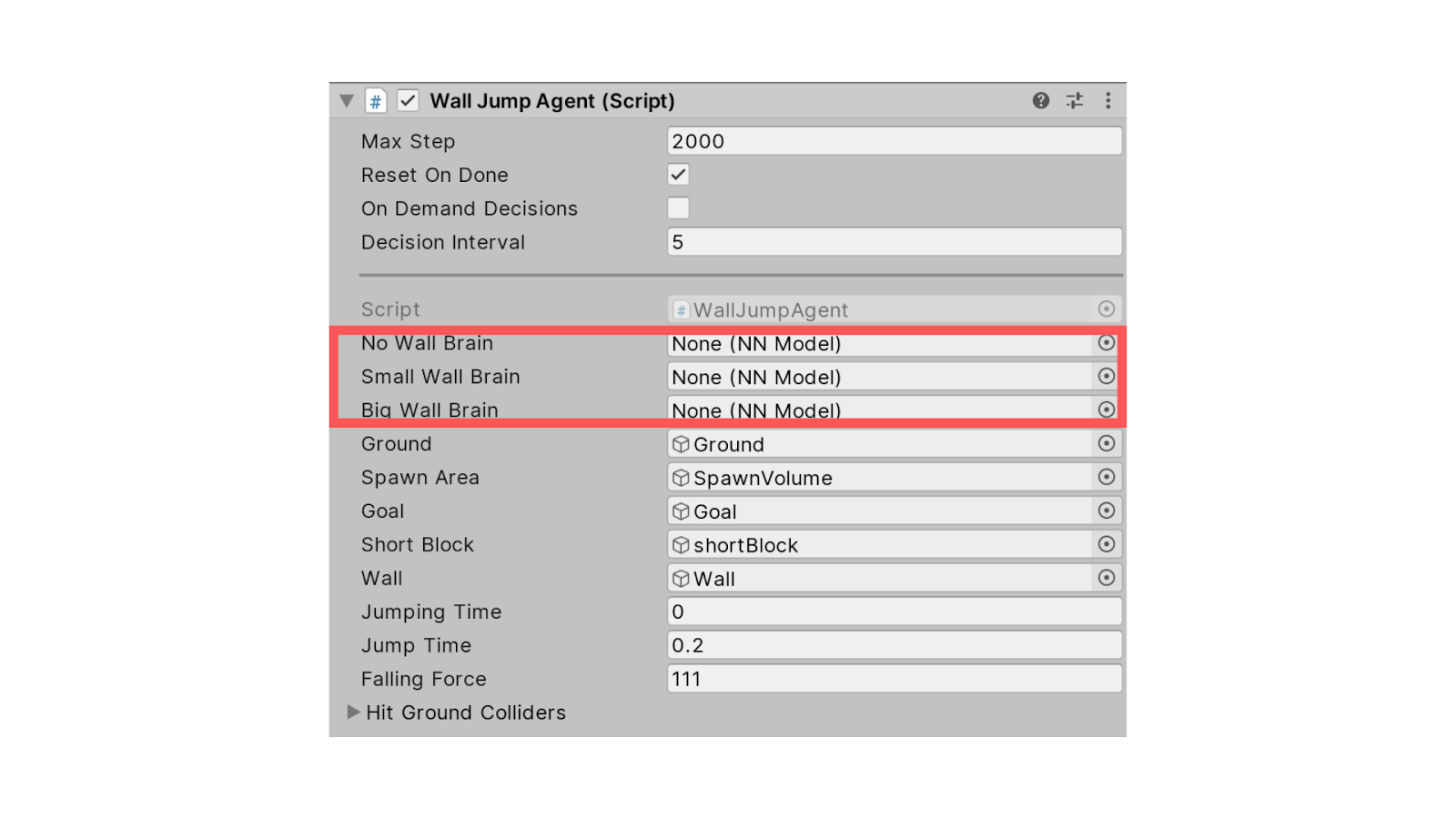
 Then in Wall Jump Agent Component, we need to remove the brains for No Wall Brain, Small Wall Brain, and Big Wall Brain situations.
Then in Wall Jump Agent Component, we need to remove the brains for No Wall Brain, Small Wall Brain, and Big Wall Brain situations.
 Now that you’ve done that you’re ready to train your agent from scratch.
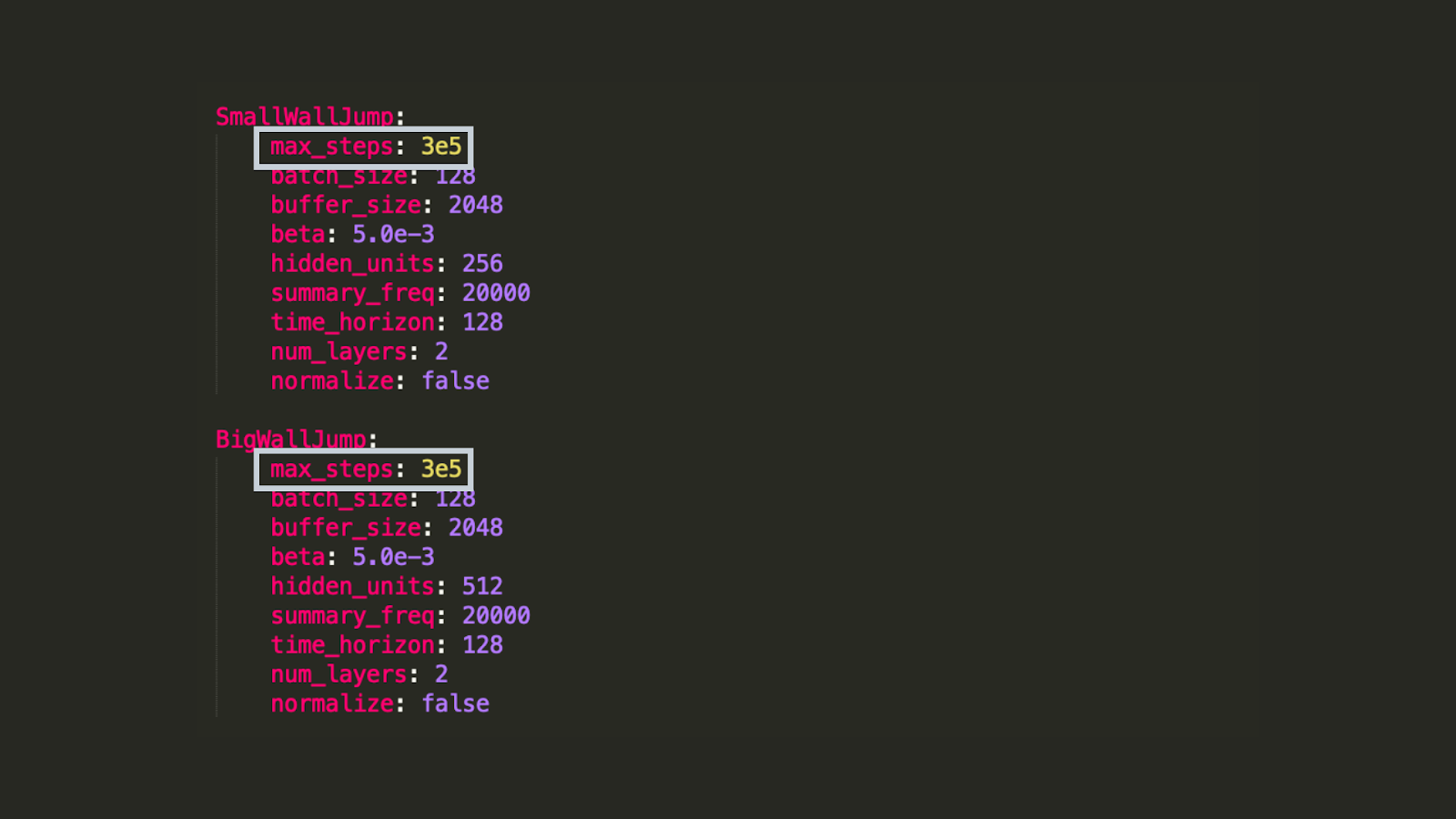
For this first training, we’ll just modify the total training steps for the two policies (SmallWallJump and BigWallJump) because we can hit the benchmark in only 300k training steps.
To do that we go to and you modify these to max_steps to 3e5 for SmallWallJump and BigWallJump situations in config/trainer_config.yaml
Now that you’ve done that you’re ready to train your agent from scratch.
For this first training, we’ll just modify the total training steps for the two policies (SmallWallJump and BigWallJump) because we can hit the benchmark in only 300k training steps.
To do that we go to and you modify these to max_steps to 3e5 for SmallWallJump and BigWallJump situations in config/trainer_config.yaml
 To train this agent, we will use PPO (Proximal Policy Optimization) if you don’t know about it or you need to refresh your knowledge, check my article.
We saw that to train this agent, we need to call our External Communicator using the Python API. This External Communicator will then ask the Academy to start the agents.
So, you need to open your terminal, go where ml-agents-master is and type this:
mlagents-learn config/trainer_config.yaml — run-id=”WallJump_FirstTrain” — train
It will ask you to run the Unity scene,
Press the ▶️ button at the top of the Editor.
To train this agent, we will use PPO (Proximal Policy Optimization) if you don’t know about it or you need to refresh your knowledge, check my article.
We saw that to train this agent, we need to call our External Communicator using the Python API. This External Communicator will then ask the Academy to start the agents.
So, you need to open your terminal, go where ml-agents-master is and type this:
mlagents-learn config/trainer_config.yaml — run-id=”WallJump_FirstTrain” — train
It will ask you to run the Unity scene,
Press the ▶️ button at the top of the Editor.
 You can monitor your training by launching Tensorboard using this command:
tensorboard — logdir=summaries
Watching your agent jumping over walls
You can watch your agent during the training by looking at the game window.
When the training is finished you need to move the saved model files contained in ml-agents-master/models to UnitySDK/Assets/ML-Agents/Examples/WallJump/TFModels.
And again, open the Unity Editor, and select WallJump scene.
Select the WallJumpArea prefab object and open it.
Select Agent.
In Agent Behavior Parameters, drag the SmallWallJump.nn file to Model Placeholder.
You can monitor your training by launching Tensorboard using this command:
tensorboard — logdir=summaries
Watching your agent jumping over walls
You can watch your agent during the training by looking at the game window.
When the training is finished you need to move the saved model files contained in ml-agents-master/models to UnitySDK/Assets/ML-Agents/Examples/WallJump/TFModels.
And again, open the Unity Editor, and select WallJump scene.
Select the WallJumpArea prefab object and open it.
Select Agent.
In Agent Behavior Parameters, drag the SmallWallJump.nn file to Model Placeholder.
 Drag the SmallWallJump.nn file to No Wall Brain Placeholder.
Drag the SmallWallJump.nn file to Small Wall Brain Placeholder.
Drag the BigWallJump.nn file to No Wall Brain Placeholder.
Drag the SmallWallJump.nn file to No Wall Brain Placeholder.
Drag the SmallWallJump.nn file to Small Wall Brain Placeholder.
Drag the BigWallJump.nn file to No Wall Brain Placeholder.
 Then, press the ▶️ button at the top of the Editor and voila!
Then, press the ▶️ button at the top of the Editor and voila!
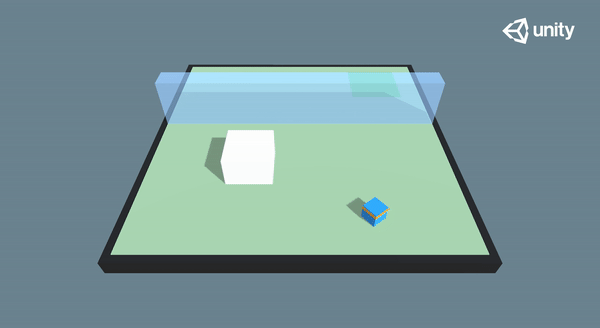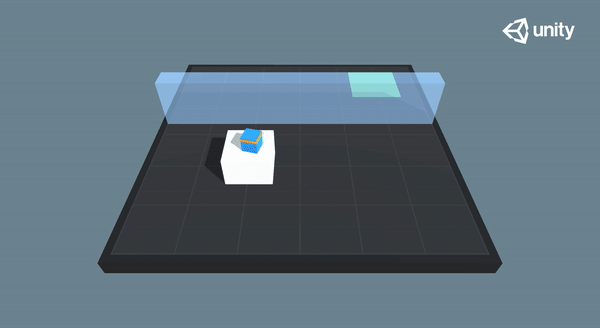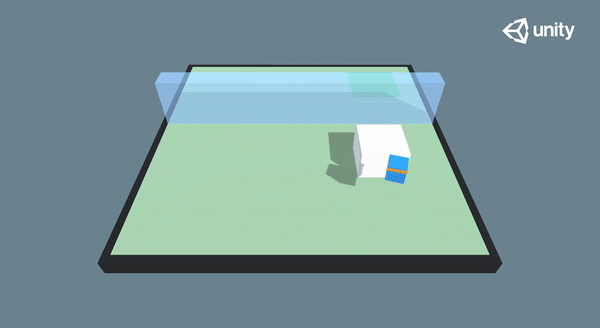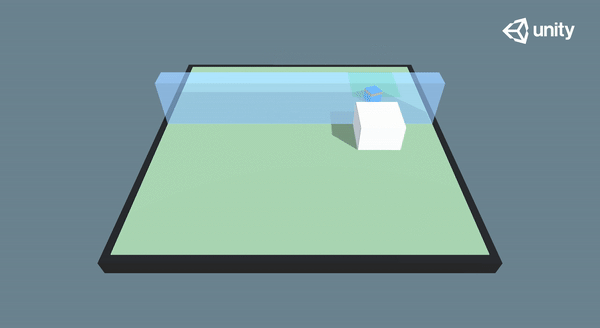 🎉
Time for some experiments
We’ve just trained our agents to learn to jump over walls. Now that we have good results we can make some experiments.
Remember that the best way to learn is to be active by experimenting. So you should try to make some hypotheses and verify them.
Reducing the discount rate to 0.95
We know that:
The larger the gamma, the smaller the discount. This means the learning agent cares more about the long term reward.
On the other hand, the smaller the gamma, the bigger the discount. This means our agent cares more about the short term reward.
The idea behind this experimentation was if we increase the discount by decreasing the gamma from 0.99 to 0.95, our agent will care more about the short term reward, and maybe it will help him to converge faster to an optimal policy.
🎉
Time for some experiments
We’ve just trained our agents to learn to jump over walls. Now that we have good results we can make some experiments.
Remember that the best way to learn is to be active by experimenting. So you should try to make some hypotheses and verify them.
Reducing the discount rate to 0.95
We know that:
The larger the gamma, the smaller the discount. This means the learning agent cares more about the long term reward.
On the other hand, the smaller the gamma, the bigger the discount. This means our agent cares more about the short term reward.
The idea behind this experimentation was if we increase the discount by decreasing the gamma from 0.99 to 0.95, our agent will care more about the short term reward, and maybe it will help him to converge faster to an optimal policy.
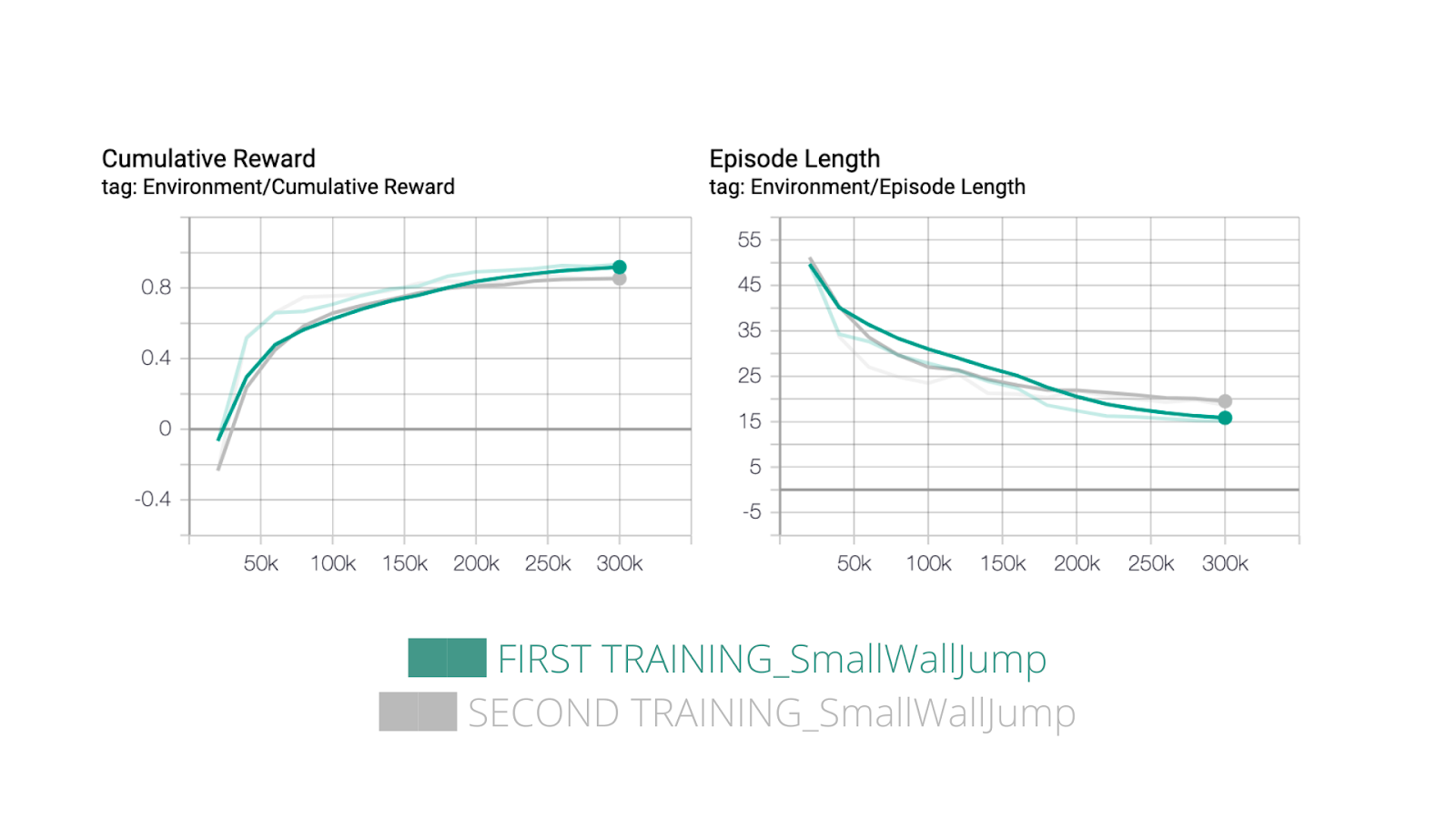 Something interesting to see is that our agent performs quite the same in case of Small Wall Jump, we can explain that with the fact that this situation is quite easy, he just needs to move towards the green grid and jump if there is a small wall.
Something interesting to see is that our agent performs quite the same in case of Small Wall Jump, we can explain that with the fact that this situation is quite easy, he just needs to move towards the green grid and jump if there is a small wall.
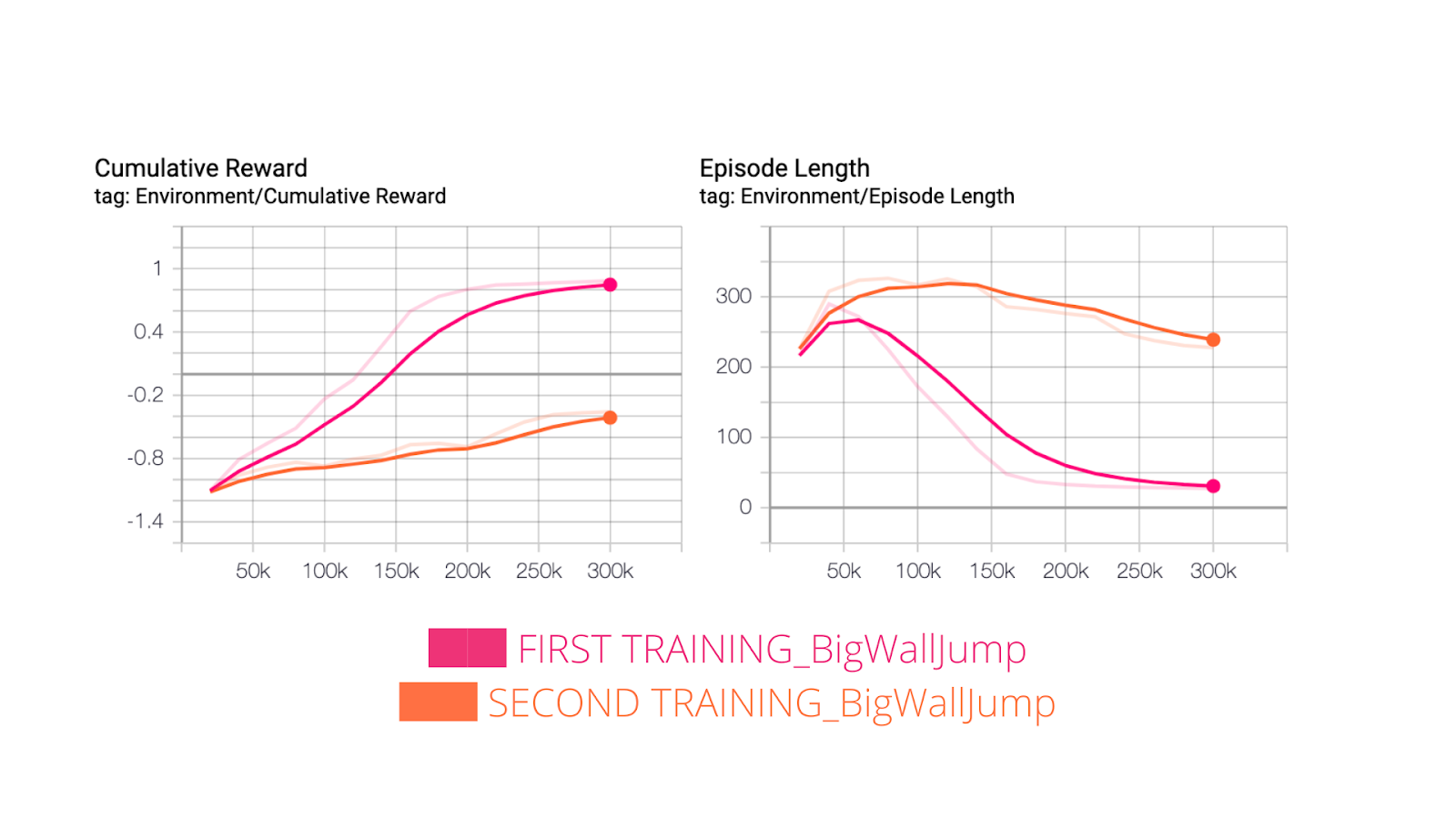 On the other hand, it performed really badly in the case of Big Wall Jump. We can explain that because our new agent cares more on short term reward, he was unable to have a long term thinking and thus didn’t really understood that he needed to push the white brick in order to be able to jump over the wall.
Increasing the complexity of the Neural Network
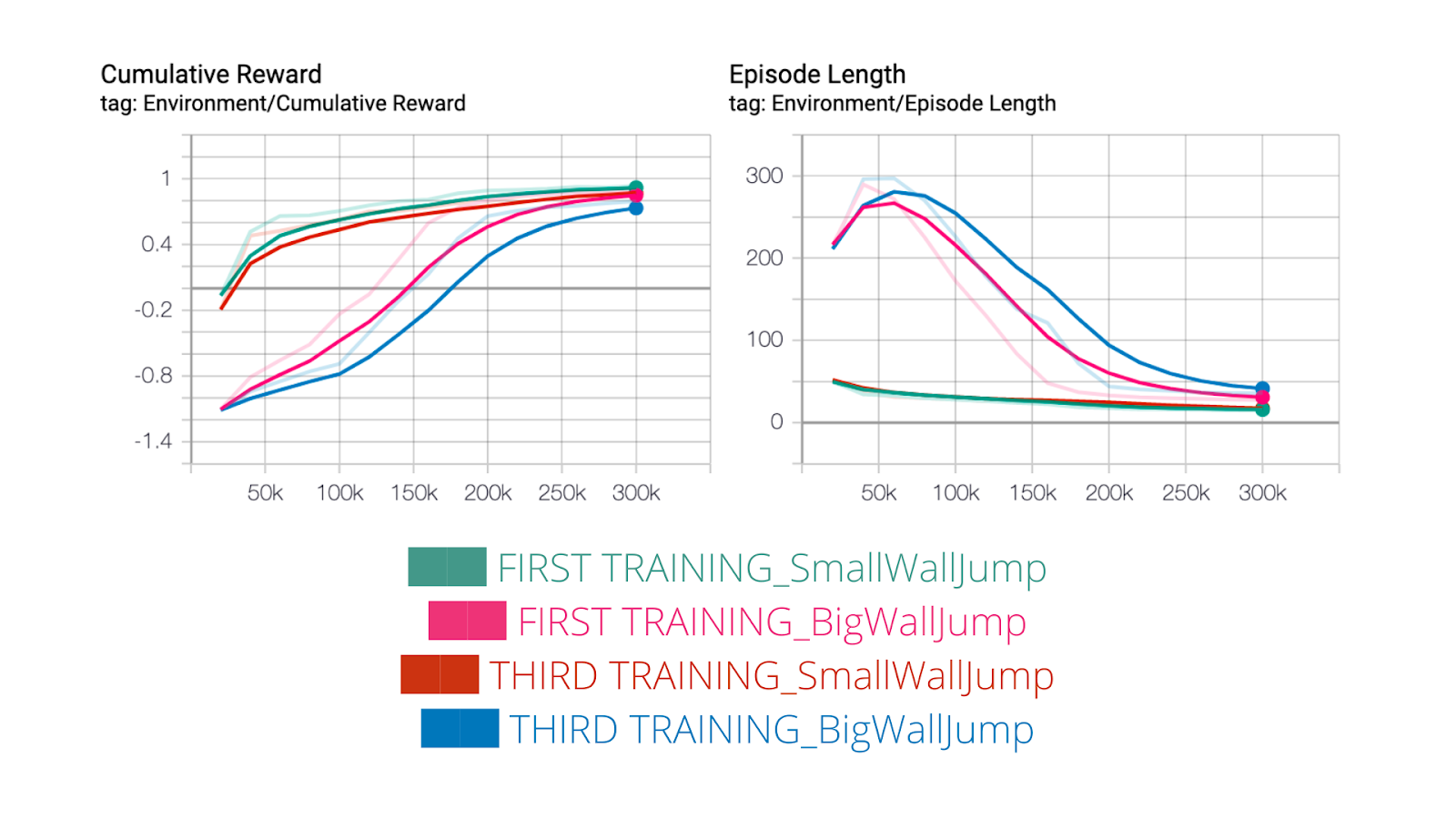
For this third and last training, the hypothesis was does our agent will become smarter if we increase the Network complexity?
What we’ve done is increasing the size of the hidden unit from 256 to 512.
But we found that this new agent performs poorer than our first agent.
It implies that we don’t need to increase the complexity of our network when we have this type of simple problem because it increases the training time until convergence.
On the other hand, it performed really badly in the case of Big Wall Jump. We can explain that because our new agent cares more on short term reward, he was unable to have a long term thinking and thus didn’t really understood that he needed to push the white brick in order to be able to jump over the wall.
Increasing the complexity of the Neural Network
For this third and last training, the hypothesis was does our agent will become smarter if we increase the Network complexity?
What we’ve done is increasing the size of the hidden unit from 256 to 512.
But we found that this new agent performs poorer than our first agent.
It implies that we don’t need to increase the complexity of our network when we have this type of simple problem because it increases the training time until convergence.
 That’s all for today! You’ve just trained an agent that learns to jump over walls. Awesome!
Don’t forget to experiment, change some hyperparameters try news things. Have fun!
If you want to compare with our experimentations, we published our trained models here.
In the next article, we’ll train a smarter agent that needs to press a button to spawn a pyramid, then navigate to the pyramid, knock it over, and move to the gold brick at the top. In order to do that we’ll use in addition to extrinsic rewards curiosity as an intrinsic one.
That’s all for today! You’ve just trained an agent that learns to jump over walls. Awesome!
Don’t forget to experiment, change some hyperparameters try news things. Have fun!
If you want to compare with our experimentations, we published our trained models here.
In the next article, we’ll train a smarter agent that needs to press a button to spawn a pyramid, then navigate to the pyramid, knock it over, and move to the gold brick at the top. In order to do that we’ll use in addition to extrinsic rewards curiosity as an intrinsic one.
